|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
Intel Math Kernel Library Performance Specifications
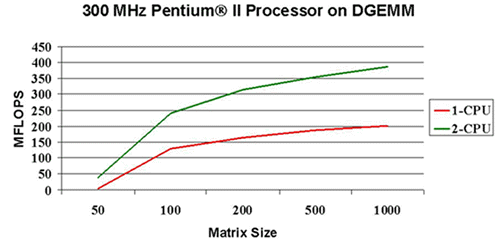
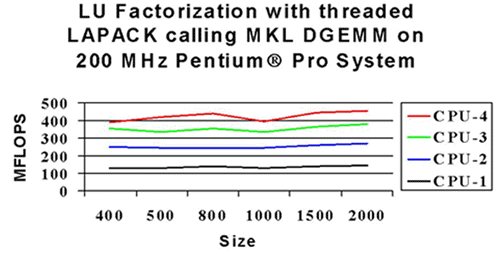
All of the Math Kernel Library routines have been optimized for high performance on the Pentium® Pro and Pentium II processors. The BLAS level 3 routines that perform matrix-matrix operations have been further optimized for efficient cache usage. This optimal cache management ensures excellent performance on a single processor. In addition, these routines have been multithreaded and scale well when run on up to four processors. The graphs that follow show double precision performance using DGEMM in two different environments. The first case shows DGEMM running on single and double 300 MHz Pentium® II processor machines. The second graph shows the performance of LU factorization using a threaded version of LAPACK calling DGEMM on single, double, and quadruple 200 MHz Pentium Pro processor machines.
|
* Legal Information © 1998 Intel Corporation